前言
据 OpenAI 的公开资料显示,近年爆火的 ChatGPT,是基于 Ray 进行的包括预训练、Fine Tune、强化学习等 ChatGPT 的训练。那让我们来聊聊Ray 这个框架吧。
背景
实际上,在2015年秋天,UC.Berkeley的 Ion Stoica教授给研究生讲系统课时,Robert和Philip 两个机器学习的学生正在做一个关于数据并行机器学习的训练,最初使用了Spark,并进行了修改叫做SparkNet,后来发现Spark 太死板,在做强化学习时,需要的计算模型非常复杂,有嵌套并行的内容发现Spark 并不擅长。于是他们研发了分布式执行引擎Ray ,主要面向未来交互式的AI,提供任务并行和高速的任务调度,并在2017年发表了论文《Ray: A Distributed Framework for Emerging AI Applications》。不同于Spark 这样的BSP 计算引擎,同一stage内的任务无法相互通信,而Ray 更加底层,更加灵活,一个任务可以启动其他任务或启动actor,它们可以相互通信,还实现了全局控制状态和调度器。
基于Ray 这项开源工作,在2019年12月,该论文的一作、二作和Ion Stoica 教授以及Michael.Jordan 教授创立了Anyscale,提供托管Ray 的服务。值得注意的是,Ion Stoica教授也是Databricks(托管Spark)的原CEO。
如今,Ray 社区非常活跃,github上已经有29.3k ⭐️,很多大厂如国外的OpenAI、Uber、Shopify等,国内的有蚂蚁集团、字节等都在生产环境广泛使用。Ray峰会Ray Summit参加的人数也越来越多,更多的公司采用Ray 作为分布式计算的框架。
Ray 框架简介
现在的机器学习等任务在性能(任务高速响应),灵活性(计算任务差异),可靠性方面都有很高要求,因此设计一个新的计算框架Ray,提出了逻辑中心控制状态板(GCS)的概念,采用分片的分布式存储系统,提供一种自底向上的分布式调度器来实现。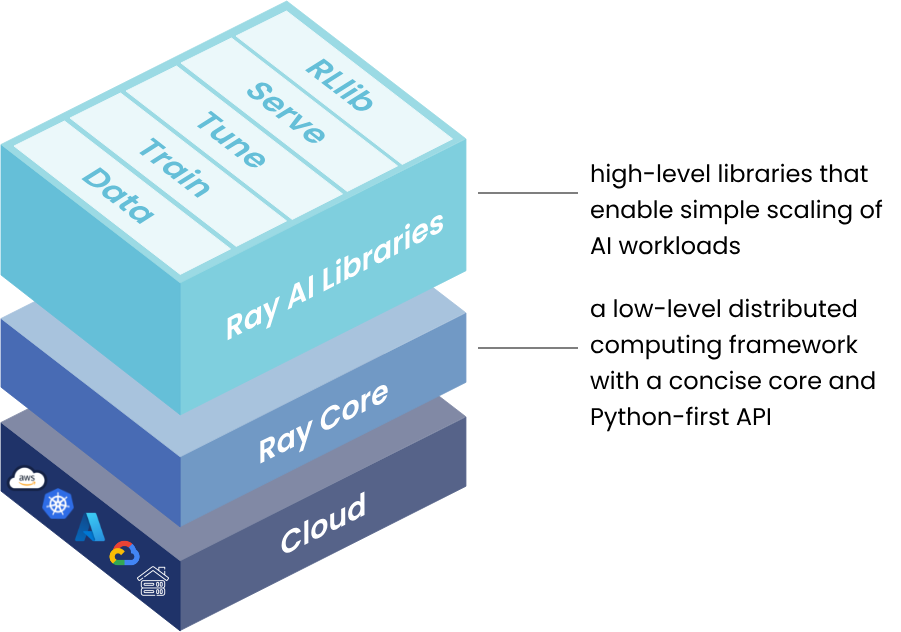
由上面的Ray 框架图来看,Ray Core即是底层的核心实现,使得开发者能基于此,在本地机器、K8s集群或者各种云上开发构建可扩展的分布式应用。
在上层,Ray 提供了一系列的原生库,用于开发和部署机器学习任务,如可扩展的数据处理库、分布式训练库、超参调优库、模型服务以及分布式强化学习库等。
机器学习应用或者数据应用增长速度远快于单个节点或者单个处理器的能力,必须使用分布式技术来处理这些工作,然而直接编写分布式应用非常困难,现在利用Ray 框架,可以方便的开发分布式任务,而不需要担心分布式组件通信、服务部署、服务发现、监控和异常恢复等。
Ray 编程模型
Ray 提供了Actor 和Task-parallel 两种编程抽象,可以使用装饰器@ray.remote 将一个函数或者一个类变成分布式的task和actor,再通过分布式的对象存储来共享和传递object 以完成分布式的协作。不依赖某一种计算模式,提供简单易用的API,使得Ray 具有通用性,很方便的与其他框架集成。
1 | import ray |
或者
1 | import ray |
Ray 采用了动态计算图机制,Actor是有状态的工作进程,Actor的任务必须使用特定的方式提交给指定的实例,可以在执行过程中修改Actor 的内部状态。在同一个Actor中,方法的执行是顺序的,无法并行。这也是保障Ray 可以重建这些对象。
值得注意的是,这些Task和Actor都是可以指定资源和使用量,如CPU、GPU或者自定义的资源。
Ray 架构设计
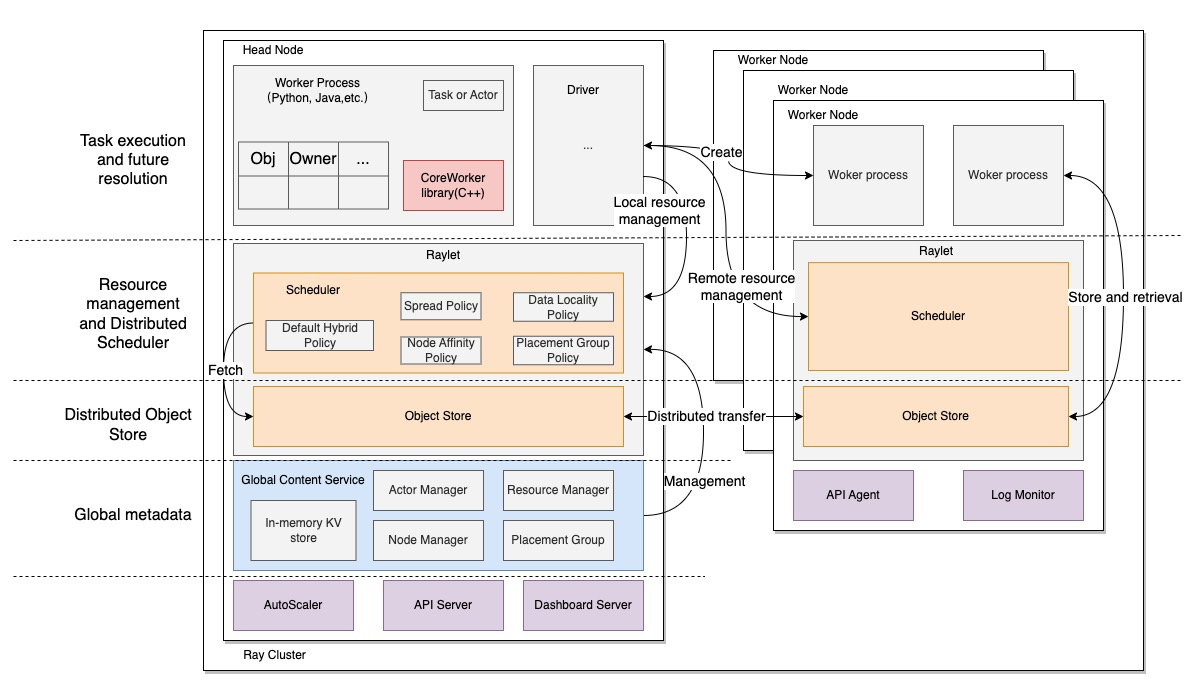
Ray 集群是由一个或者多个worker 节点组成,其中一个节点被指定为head 节点。每个节点都有:
- 一个或者多个worker进程,要么是无状态的remote function,要么是actor。每个工作节点会存储一些内容:
- ownership 表,worker 引用的对象的系统元数据,例如引用计数(老iOSer 还记得MRC和ARC的爱恨情仇么)和对象位置,有关所有权归属机制的详细介绍可以看Ray 团队在NSDI 2021上发表的论文《Ownership: A Distributed Futures System for Fine-Grained Tasks》。
- 一个进程内存储,存放一些小对象(<100KB)
- raylet 进程,用于管理每个节点的共享资源,与worker 进程不同的是,raylet在所有并发的job中是共享的,主要有2个组件运行在单独的线程:
- scheduler 组件,负责资源管理,任务调度和完成,将Task的参数存储在Object Store中;目前支持多种调度策略。
- object store 组件,存储和转移大对象。
集群内部大部分都是通过gRPC 调用通信的,保障集群内部通信效率。Ray 的三板斧包括:
- 分布式调度(Distributed Scheduler):运行在每个节点的Raylet进程上,负责资源管理,task 放置的位置, 保证 task 运行所需要的参数对象可以从分布式对象存储的对象中获取。每个 Raylet 组件会跟踪本地节点的资源, 当一个资源请求被同意之后,Raylet 就会减少本地可用资源,一旦资源被使用完之后返还回来了,Raylet 又会增加本地的可用资源, 所以 Raylet 有一个强一致性的本地的可用资源的视图。同时,Raylet 也接收来自GCS 服务的一些关于其它节点的资源使用的信息, 这个信息(最终一致性)对于分布式调度是很有用。比如,在集群范围内,可以多种不同策略(数据位置、节点亲和性等)的调度。GCS 会定期(默认100ms)从每个节点的 Raylet 拉取本地节点的可用资源,然后将这些信息通过广播的方式告知所有节点的 Raylet。
- **分布式对象存储(Distributed Object Store)**:分布式共享内存存储,在同一个节点上可以实现不同的woker进程之间能够零拷贝(zero copy)地访问共同的数据,不同节点上也可以引用。具体实现采用了Apache Arrow中的Plasma store,负责存储和转移大对象,如果plasma store满了之后,会通过LRU 机制剔除陈旧的对象溢出到外部存储(disk或者s3等)。
- **全局状态控制器(Global Controler Service)**:之前的只在head节点,v2版本后支持了容错,可以运行在任意节点或多个节点。主要包含节点管理,资源管理,PlacementGroup管理(用于实现gang-scheduling - all or nothing调度)
另外有些额外的辅助服务,如AutoScaler、Job Commit、监控等,使得集群管理更加简单。
在一个Ion 的访谈,他也提到,从根本上说,Ray是一个RPC(远程过程调用)框架,加上一个actor框架,以及一个对象存储,它允许你在不同函数和actor之间通过引用(reference)高效传递数据。
字节在开源社区针对Ray 贡献了Kuberay 项目,用于Ray 集群的k8s部署管理。
每个 Ray Cluster 由 Head 节点和 Worker 节点组成,每个节点是一份计算资源,可以是物理机、Docker 等等,在 K8s 上即为一个 Pod。启动 Ray Cluster 时,使用 Kuberay 的 Operator 来管理整个生命周期,包括创建和销毁 Cluster 等等。Kuberay 同时也支持自动扩展和水平扩展。Ray Cluster 在内部用于收集负载的 Metrics,并根据 Metrics 决定是否扩充更多的资源,如果需要则触发 Kuberay 拉起新的 Pod 或删除闲置的 Pod。
用户可以通过内部的平台使用 Ray,通过提交 Job 或使用 Notebook 进行交互式编程。平台通过 Kuberay 提供的 YAML 和 Restful API 这两种方式进行操作。
Ray 适用性
根据Ray 的特点,适合以下几类应用范围:
- 构建机器学习平台
Ray 及提供的原生库可以和其他框架(如Pytorch,tensorflow)集成,可以为ML 平台提供统一的计算运行时,也能组成端到端的ML Workflow。 - 离线批量处理
具有高效的缓存模型和高性能数据Pipeline,字节也在用基于 Ray 的大规模离线推理 - 深度学习
高性能的数据集成,支持CPU/GPU 异构集群,以及自带多种超参搜索算法和并行训练。
我们在项目上是使用Ray 作为AutoML 库进行模型的超参微调和分布式并行训练的。 - LLM / 生成式AI
灵活的模型并行(支持集成DeepSpeed和Alpa),可以利用更小、更便宜的GPUs。
实际上,Ray 作为通用分布式计算引擎,应用范围非常广,很多大厂也在同步扩展到不同的场景中去。如蚂蚁集团的实践:2023年终总结系列: Ray在蚂蚁集团生产规模达到100万核
Ray 相关
- Pathways
Google 在2022年3月发表了PATHWAYS: ASYNCHRONOUS DISTRIBUTED DATAFLOW FOR ML论文,介绍了面向机器学习的异步分布式数据流Pathways 框架,且使用该框架训练出了5400亿参数的PaLm 大模型。文中也多次提到Ray 的设计,但Pathways是谷歌闭源的,而且为TPU做了很多专门的设计,注定失望了。。
- Sky Compute
在2021年 UC.Berkeley 又提出下一代云计算架构The Sky Above The Clouds ,成立了SKY computing lab(提出Ray 的实验室是叫Rise Lab) ,实现真正上天了- -!;其希望将现有的分散的云市场变成像互联网一样可连接且易于使用的公共市场,让SkyPilot 作为** “intercloud brokers” **,而目前Ray 正作为SkyPilot的底座。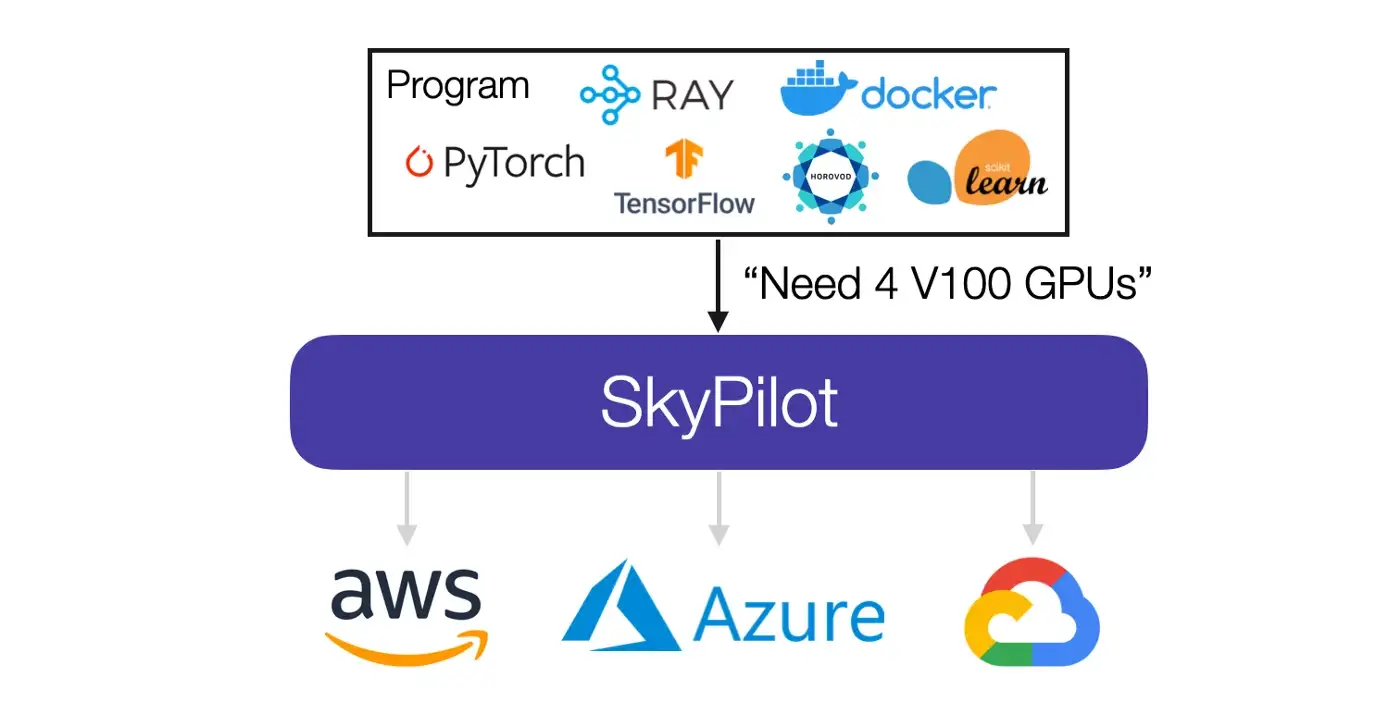
如上图,假设给定一项工作及其资源需求(CPU/GPU/TPU),SkyPilot 会自动找出哪些位置(区域/区域/云)具有运行该工作的计算能力,然后将其发送到成本最低的位置执行。
总结
本文介绍了通用分布式计算框架Ray 的背景起源,通过深入Ray 的编程模型和架构设计,了解Ray的特点和优势,进而介绍了Ray 作为通用分布式计算框架的应用场景,最后介绍了与Ray 相似,Google的框架Pathways 和UC.Berkeley 下一步的野心–Sky Compute。希望本文能给在做分布式应用的同学带来帮助(给Ray 打广告来了)。
参考
Ray: A Distributed Framework for Emerging AI Applications
How Ray, a Distributed AI Framework, Helps Power ChatGPT
Ion Stoica — Spark, Ray, and Enterprise Open Source
Scaling Distributed Machine Learning with the Parameter Server