前言
在当今快速发展的人工智能领域,构建高效、可扩展的机器学习模型是至关重要的。随着云计算平台的普及和分布式计算框架的发展,企业智能应用开发者越来越多地将注意力集中在如何利用这些技术来提高机器学习模型的开发效率和性能。
现如今,云计算平台提供了很多端到端的功能和基础设施管理,以帮助企业在机器学习开发流程中实现合规性、风险控制以及成本监控等,使开发者更加关注模型研发以提升整体效率。比如AWS 的Sagemaker,Azure的Machine Learning Studio和GCP的AI Platform等,而Databircks 提供可以基于多云基础设施的统一Data & AI 工具平台。
而新兴的开源通用分布式计算框架Ray 也在不断演进,它在统一底层框架的基础上提供了丰富的AI库。我们可以轻松的使用该上层库在任何机器或者云平台上构建机器学习开发流程。
在本文中,我将介绍分布式计算框架Ray 在Databricks平台上进行机器学习模型开发的项目实践。
Machine Learning in Databricks
Databricks 为机器学习模型开发提供了一系列的工具与功能:
- Databricks Runtime:是一个经过优化的运行时环境,支持常用的机器学习框架和库,如TensorFlow、PyTorch和Scikit-learn等,在项目上就是使用13.3 LTS ML (includes Apache Spark 3.4.1, Scala 2.12)版本,其中还包含模型可解释库SHAP等第三方分析库;同时提供高效的分布式计算和存储,可以基于此为模型训练提供稳定和高性能的环境。
- MLFlow:是一个开源的Machine Learning Lifecycle Platform, 也是由Databricks 发起和主导开发的。能帮助开发者进行model tracking和registry。
- Databricks Delta:是databricks 提供的高性能数据湖解决方案,结合了数据仓库的可靠性和数据湖的灵活性,且提供了事务性ACID 操作,自动数据版本控制、增量数据湖更新等功能,使得数据管理和处理更加简单可靠,对比DVC(https://dvc.org/) 在管理非结构化数据集时有明显优势。
- Databricks Workflow: 允许用户在Databricks 上自动执行任务流的调度器,可以自定义脚本执行数据处理、模型训练、评估和部署等任务。类似Airflow 等调度器,它也可以配置作业的调度时间,触发条件和执行环境等,是实现CD4ML(https://martinfowler.com/articles/cd4ml.html) 流程的关键
- Databricks AutoML:是Databricks提供的自动化机器学习功能,可以自动化的进行特征工程、模型选择和调优,以帮助用户快速构建和优化机器学习模型
我在Databricks 平台上构建了机器学习模型开发的pipeline,基于CD4ML 的理念,设计并实现了数据集版本管理、模型训练、数据与模型检测、模型管理等workflows。
简版架构图如下: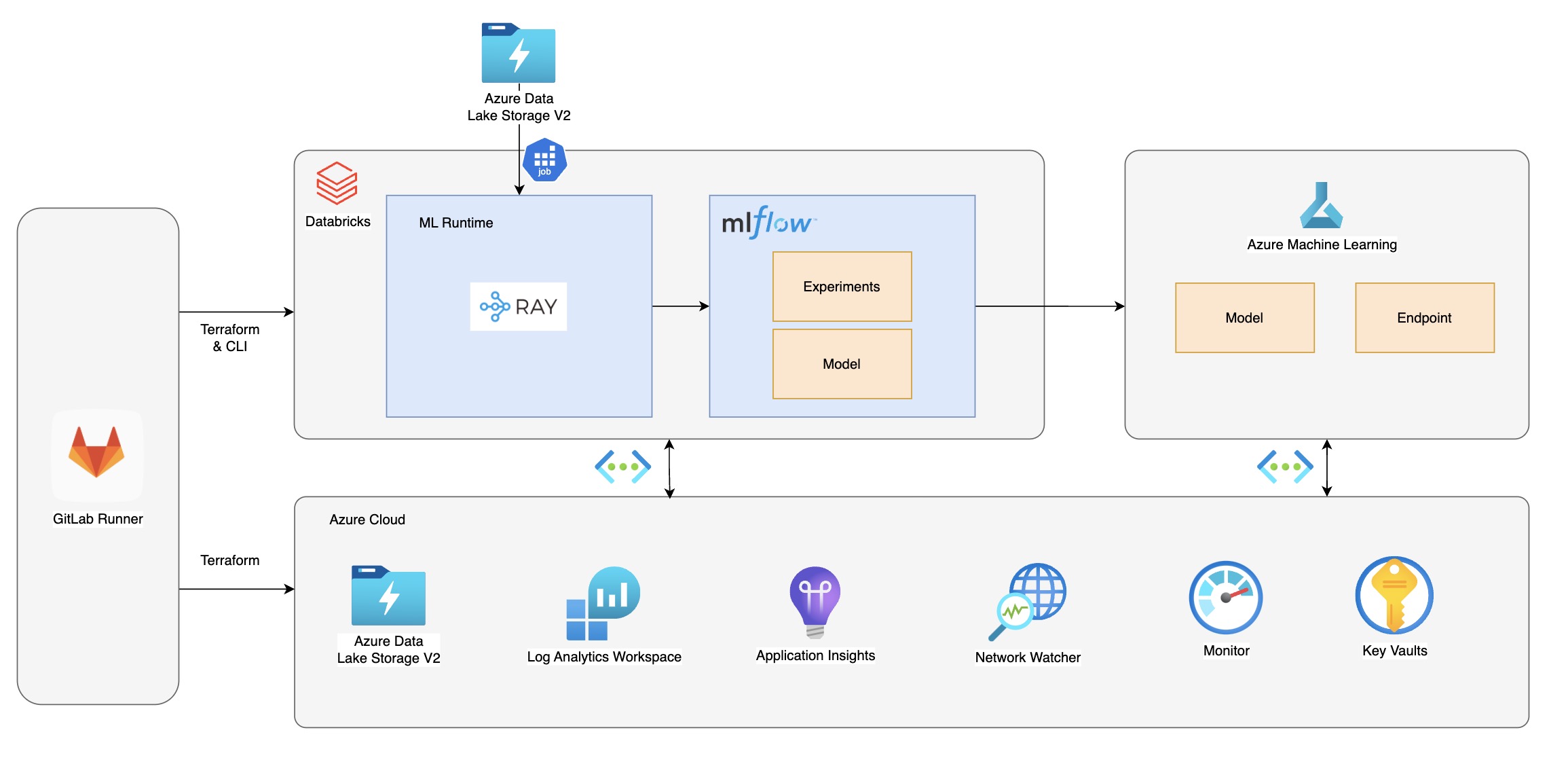
基础设施方面
基于infrastructure as code 原则,使用Terraform 管理多个环境(sit、uat和prod)的资源,包括databricks workspace、network、access control、stroage、cluster等。
数据集管理方面
使用Databricks delta table管理图像数据集,对于数据集的调整,通过delta table的版本标记来跟踪。
同时使用Fastdup进行数据集清洗,使用Alibi Detect 对比线上数据和训练数据集的差异,设计实现data drift 检测流程。
模型开发方面
- 任务管理:使用Databricks CLI 创建和管理模型开发过程中的各个workflows,采用deploy code 模式,在sit 环境使用采样数据集进行功能开发,在prod上运行基于全量数据集的各个workflow.
- 模型训练:设计支持多个超参自动选择或采样策略的AutoML 流程,利用分布式数据并行充分利用多GPU 的资源,实现自定义early stopping策略,加速训练时间,并且打通MLFlow 在模型训练过程中指标trace 和版本管理
- 模型监控:收集线上反馈数据,检测model drift。在Databricks 平台上可以结合SQL Warehouse、Query、Alert 和Dashboard 做到模型监控数据的落地告警和可视化。
- 模型可解释性:Databricks ML Runtime中还集成了SHAP (SHapley Additive exPlanations) 这样的模型可解释性的博弈论方法库,对于一些corner case的分析带来一定的帮助。
总体而言,结合Databricks Platform,可以快速建立高效合规的机器学习开发环境。
在Databricks上使用Ray AI Libraries
那大家可能会问:既然Databricks 平台提供了模型开发的端到端工具和功能,那进行机器学习模型开发为什么还使用Ray呢?
实际上,进行大部分机器学习模型开发时,直接使用Databricks 平台提供的能力也是可行的,但由于项目上的数据集是图像这种非结构化数据。
而现有Databricks 不支持图片数据集的AutoML Experiment。

众所周知,模型训练也是一个炼丹的过程。在模型训练流程中,我们通过不断的调整模型结构和超参数,以训练出一个最佳性能的模型。这个过程中使用AutoML 方法提供模型开发效率,节省训练资源。
对于Ray 提供的AI库,我主要使用了Ray Train 和Ray Tune, 主要用于模型训练和参数微调。结合Databricks 平台,实现了分布式数据并行训练,自动超参调优,以及自定义提前停止策略等功能。
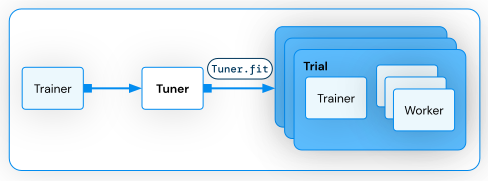
对于分布式数据并行训练,Pytorch 提供了DDP(Distributed Data Parallel) 的实现,而Ray Trainer也对DDP 进行了兼容和封装,只需要简单几步就可以实现分布式数据并行,具体的代码可以参考这篇文章Ray: Get Started with Distributed Training using PyTorch
下图是在Databricks 上使用多GPU 进行模型训练时的机器监控图: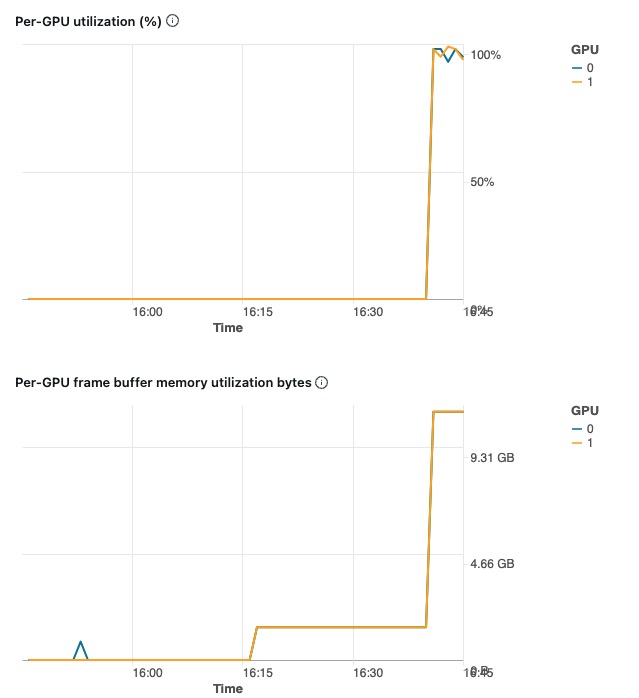
值得一提的是,在大模型盛行的当下,Ray 结合DeepSpeed 提供的ZeRO 方法对模型进行数据并行和模型并行等多种显存优化的训练。
对于超参数调优,Ray Tune 提供以下方式:
- 对超参集合,可以自定义搜索空间,提供Grid,Choice等方式
- 多种开箱即用的搜索算法,如PBT,ASHA等
- 利用各种尖端优化算法,结合scheduler 自定义提前停止策略,甚至在训练过程中调整超参以优化训练,节约成本
- 可以自定义训练任务的资源,进行多GPU的分布式并行训练(同时进行多个训练评估任务)
与此同时,我还使用Ray 集成了MLFlow trace,通过Azure DCE(Data Collection Endpoint) 和 DCR(Data Collection Rule)将训练过程和结果的日志记录到Azure Monitor中,将训练模型及运行日志保存到Azure Storage Account,实现模型训练过程的全链路监控与记录保存,以便问题排查和分析追溯。
总结
本文阐述了Databricks Platform 为机器学习模型开发提供的各种功能,通过项目实践方案介绍以及Ray 提供的AI库使用实践,让大家了解进行机器学习模型开发落地的过程,探讨一些最佳实践。由于篇幅原因,整个实现过程还有很多细节和落地注意事项未说明,有想进一步了解和沟通的同学,欢迎来找我一起探讨和总结。
参考
Train with DeepSpeed ZeRO-3 and Ray Train